Recent advances in video diffusion have enabled the development of “world models” capable of simulating interactive environments.
However, these models are largely restricted to single-agent settings, failing to control multiple agents simultaneously in a scene.
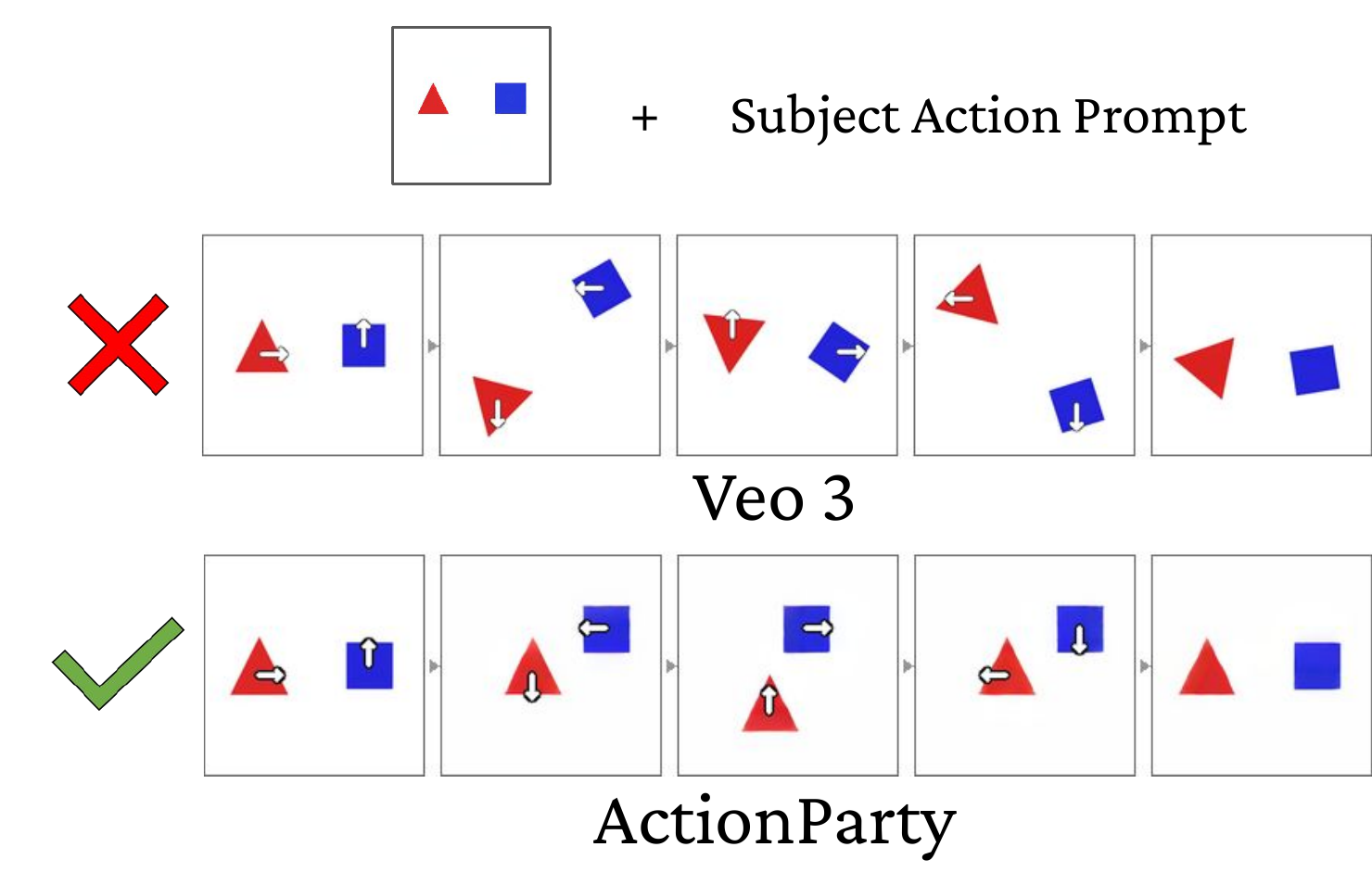
In this work, we tackle a fundamental issue of action binding in existing video diffusion models, which struggle to associate specific actions with their corresponding subjects.
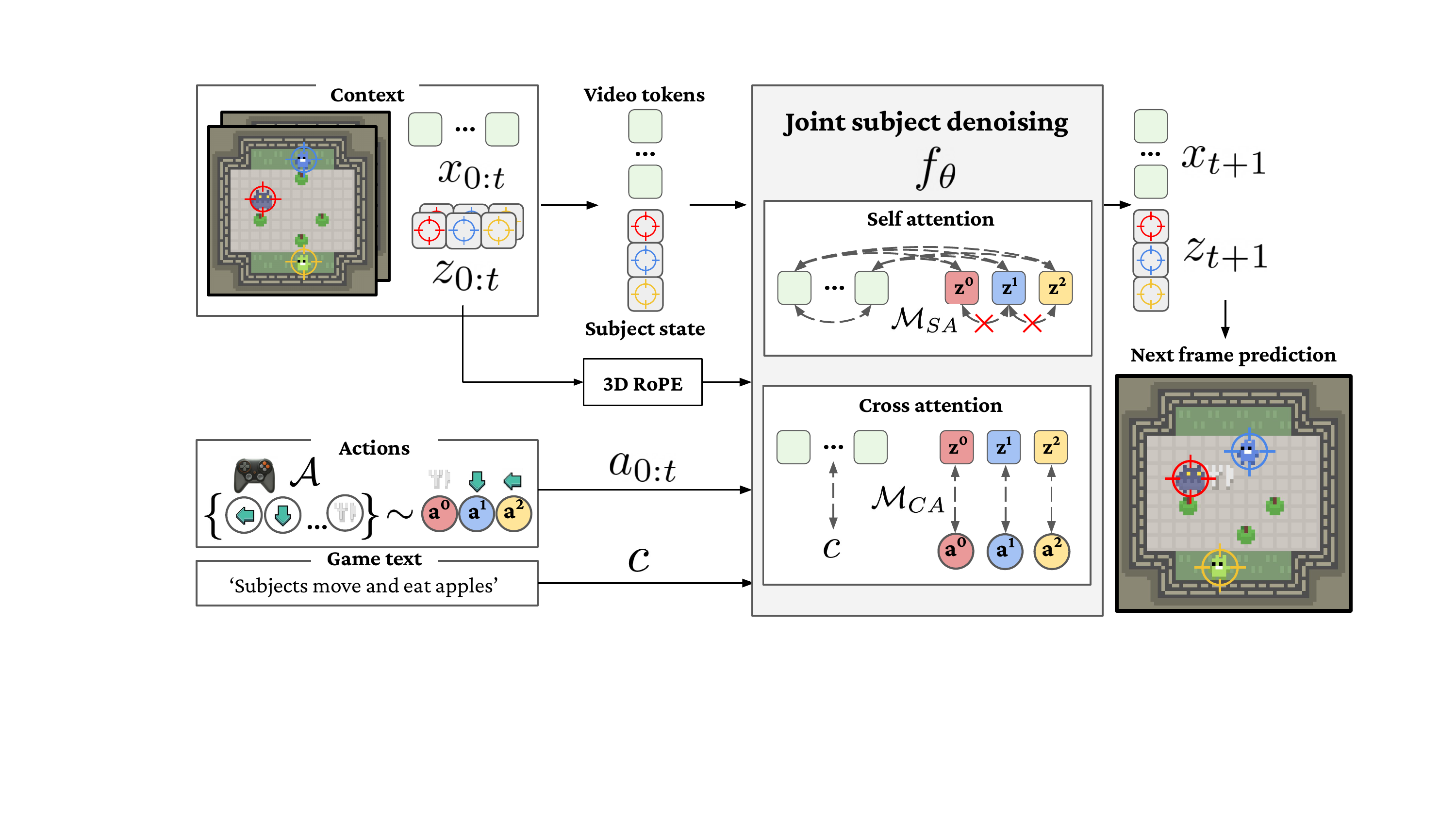
We propose ActionParty, an action-controllable multi-subject world model for generative video games.
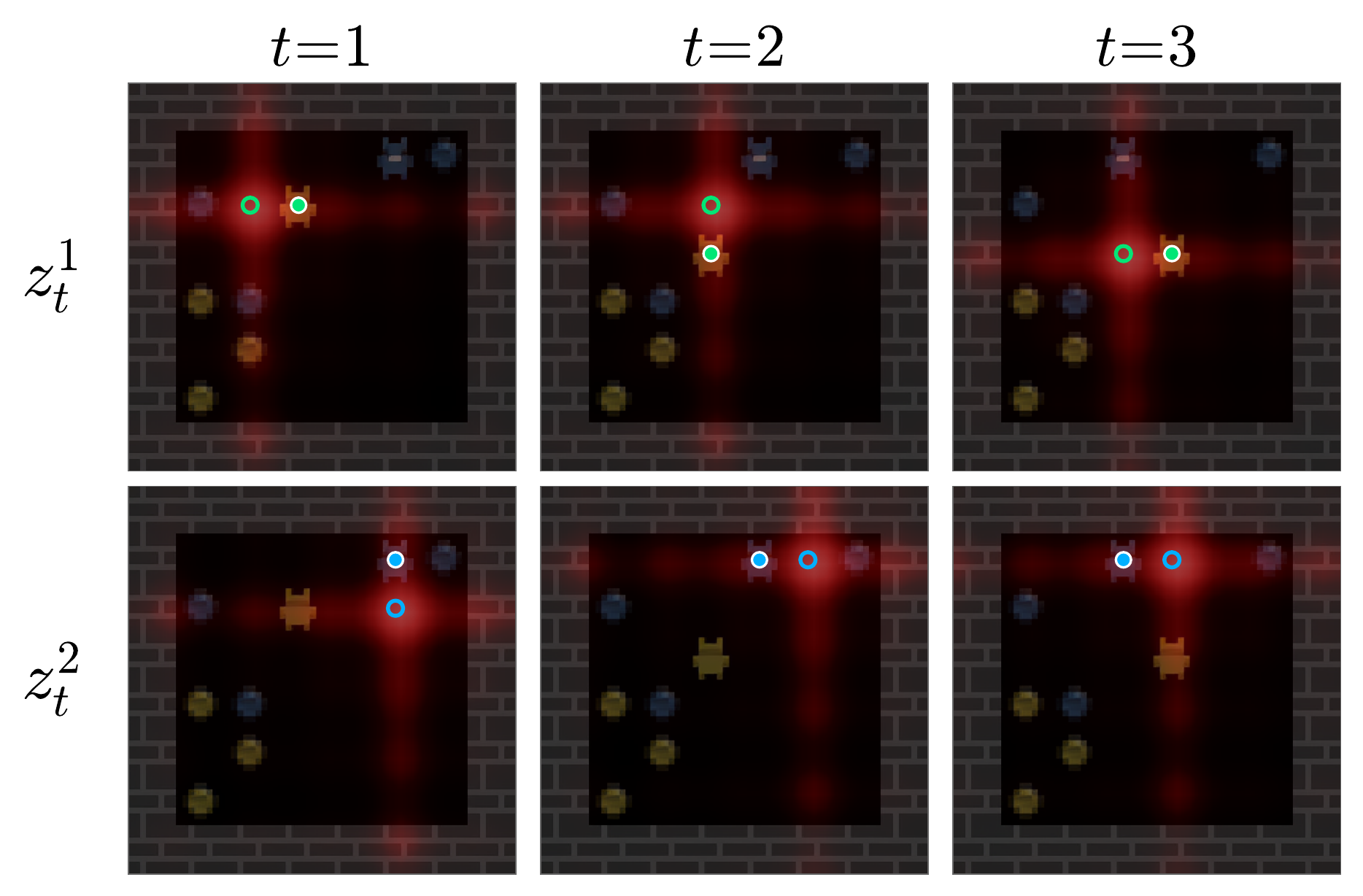
It introduces subject state tokens, i.e. latent variables that persistently capture the state of each subject in the scene.
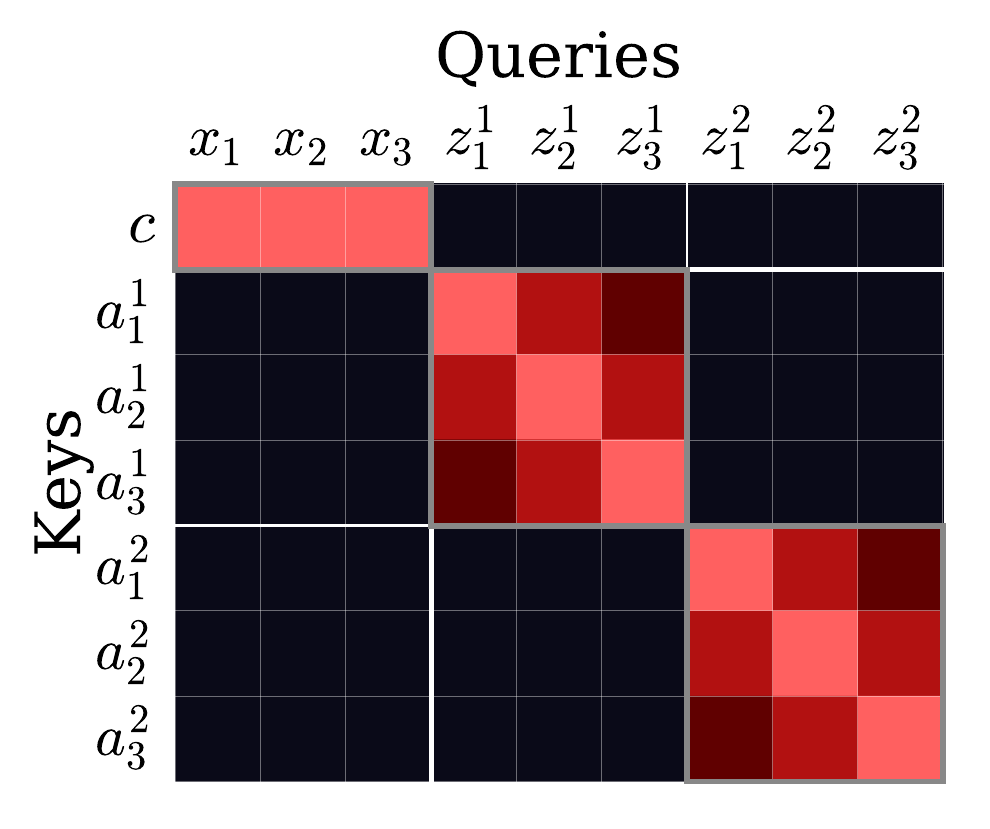
By jointly modeling state tokens and video latents with a spatial biasing mechanism, we disentangle global video frame rendering from individual action-controlled subject updates.
We evaluate ActionParty on the Melting Pot benchmark, demonstrating the first video world model capable of controlling up to seven players simultaneously across 46 diverse environments.
Our results show significant improvements in action-following accuracy and identity consistency, while enabling robust autoregressive tracking of subjects through complex interactions.
See more examples for generations across all 46 games.